
Looking for getting hold of large quantities of data?
All of us are, aren’t we?
The question is, how do we do it?
Do you copy and paste it from multiple sources, manually?
Naah! It’s time-consuming and not really viable.
So there’s only one way out: web scraping which is an automated mechanism to extract large quantities of data from websites in a clean and efficient way and that too in no time!
Let’s say you want to set it up in-house and start scraping on your own. Of course, you can but it will entail a whole lot of human and technological resources that you may not be able to afford.
You will need to, for example, hire a technical person to constantly monitor your scraper and have to have a large data storage facility.
And then what if you get blocked?
It sounds ominous!
What’s the alternative? You might ask!
Well, all you need to do is get hold of a robust web scraping software/tool that can automate the web scraping process and relieve you of all the burden of monitoring and managing a web scraping process in-house.
Oh yes, you might think that there are hundreds of tools in the market and it’s mind-boggling to choose one from it.
No worries. We have put together a comprehensive analysis of top 10 web scraping tools for you to choose from.
Let’s take a plunge!
What is a Web Scraping Tool?
A web scraping tool is a mechanism to extract data automatically from the web. While you can do it manually by copying and pasting, it’s time-consuming and not so reliable.
In other words, you cannot hope to get the data in an accurate and fast way manually. This is where a web scraping tool can be a great help. It enables you to scrape whatever data you need in an accurate and quick way in an automated fashion.
How Does Web Scraping Work?
Web scraping is the process of automatically mining data or collecting information from the Internet.
At the end of the web scraping process, we got final data (images, texts, table data, etc.) in structured format like CSV, JSON , EXCEL or XML.
Below, we’ve described in detail just how the web scraping process:
1. Request-Response
The first simple step in any web scraping program (also called a “scraper”) is to request the target website for the contents of a specific URL.
In return, the scraper gets the requested information in HTML format. Remember, HTML is the file type used to display all the textual information on a webpage.
2. Parse and Extract HTML
When it comes to Parsing, it usually applies to any computer language. It is the process of taking the code as text and producing a structure in memory that the computer can understand and work with.
To put it simply, HTML parsing is basically taking in HTML code and extracting relevant information like the title of the page, paragraphs in the page, headings in the page, links, bold text etc.
For parsing and extracting, general methods text pattern matching using regex, DOM parsing, etc. used by people.
3. Download Data
The final part is where you download and save the data in a CSV, JSON or in a database so that it can be retrieved and used manually or employed in any other program.
With this, you can extract specific data from the web and store it typically into a central local database or spreadsheet for later retrieval or analysis.
Who Are the Top 10 Web Scraping tools / software?
The below is the list of best web scraping services identified by QuickEmailVerification through ongoing exhaustive analysis.
We carried out this comprehensive analysis based on the following three key parameters of features, customer support and price.
Let’s get started.
1. ProWebScraper
ProWebScraper is the one of the most compelling web scraping tools, out of all the tools we tried. It emerges with its world-class customer service and super low prices.
ProWebScraper helps you extract data from any website. It’s designed to make web scraping a completely effortless exercise. ProWebScraper requires no coding, simply point and click on the items of interest and ProWebScraper will extract them into your dataset.
What makes ProWebScraper standout
Free Scraper Setup in 2 Hours
- For any non-technical person it’s a bit difficult to understand terminology of web scraping and configure the scraper on their own and to then download the data.
- ProWebScraper is providing “Free Scraper Setup” service in which dedicated experts will build scrapers for users within 2 hours, deliver at user’s account and guide every step of the way, so you can get data you want.
- Just fill up the very simple form with all your needs and you can rest assured that they will provide you needed data in json or csv format as soon as possible.
- ProWebScraper is the only company which provides Free Setup with dedicated experts, other companies are charging extra fees for that.
Lowest Prices
- ProWebScrapers was created to offer the best web scraping tool for those with high web scraping needs, hence ProWebScraper offers some of the lowest possible rates on the market.
- For example (monthly plans listed below):
- Scrape 10,000 pages for only $70
- Scrape 50,000 pages for only $250
- Scrape 100,000 pages for only $375
Extract Data From Dynamic Websites
- JavaScript, AJAX or any dynamic website, ProWebScraper can help you to extract data from all without getting blocked.
- Also, you can extract data from a site with multiple levels of navigation
- Whether it is categories, subcategories, pagination or product pages.
ProWebScraper also provides powerful APIs to allow users to integrate a steady stream of high-quality web data into your business processes, applications, analysis tools and visualization software.
In short, With ProWebScraper, you can scale it up and automate the web scraping process so that you can focus on the core of your business rather than spending time setting up and maintaining scrapers on your own.
Cost:
- Pay-as-you go. No monthly payments or upfront fees.
- Basic plans begin at $50 for 5000 page credits (1 page credit = 1 page successfully scrape).
- They also offer large scale scraping plans starting at $500 for 100,000 page credits that is the lowest by far on the market and credit never expires.
- Monthly Plans are also available : Basic Plans starts at $40 for 5000 page credits.
Free Trial: Yes, ProWebScraer offers 1000 pages scrape for free. No credit card is required to sign up for free service.
Type of Software: Web-based
Features:
User Interface:
- ProWebScraper tool designed to make web scraping completely effortless exercise
- Any non technical can build scrapers using ProWebScraper by their own.
- Anyone who knows how to browse the web, he/she can build scrapers using ProWebScraper.
- Just Point and Click on the desired data, and run scraper to extract them in seconds, It’s that easy!
Which web data can it scrape?
- Texts
- Table data
- Links
- Images
- Numbers (lat-long, prices, etc…)
- Key – Value Pairs
Data Download formats: JSON, CSV, and Excel
Scrape and download images?: Yes
Scraping Listing pages, Detail Pages: Yes
You can use chaining functionality of prowebscraper which can help you to retrieve all the detail page data at the same time.
Can it Scrape multiple pages / bulk pages?: Yes
- Scrape data from pagination URLs (like: page link, infinite scrolling, load more button)
- Scrape thousands of pages of Same HTML
Can it scrape data by scheduling (scrape latest data by hourly, daily, weekly, etc)?: Yes
- With Prowebscraper, You can set up a custom cronjob also.
Custom Selector to select hidden / complex data: ProWebScraper support Xpath and CSS Selector tool to select hidden / complex data
Custom Setup: ProWebScraper support team will do setup and provide custom scraper as per your requirements without charging any extra fees.
Regex to find text that matches a pattern?: Yes
Can it handle website HTML changes?: Yes
- ProWebScraper monitor particular field HTML on daily basis to check whether html changed or not
- If html change, prowebscraper will send mail with detail
Can it prevent scraper from getting blocked while scraping?: Yes
ProWebScraper rotates IP addresses with each request, from a pool of millions of proxies across over a dozen ISPs, and automatically retries failed requests, so you will never be blocked.
Data retention in days?:
- 15 days
- Custom data retention available on request
API integration: REST API available to directly integrate craigslist feed data to your business process
Scalable:
- It can run multiple scrapers at same time.
- It can scrape thousands of pages on a daily basis.
Third-party Integration: ProWebScraper currently does not provide integration with any third party tools.
Learn about the product: Documentation: https://prowebscraper.zendesk.com/hc/en-us
Customer Support: Email Support for 24 * 7 business hours
2. Mozenda
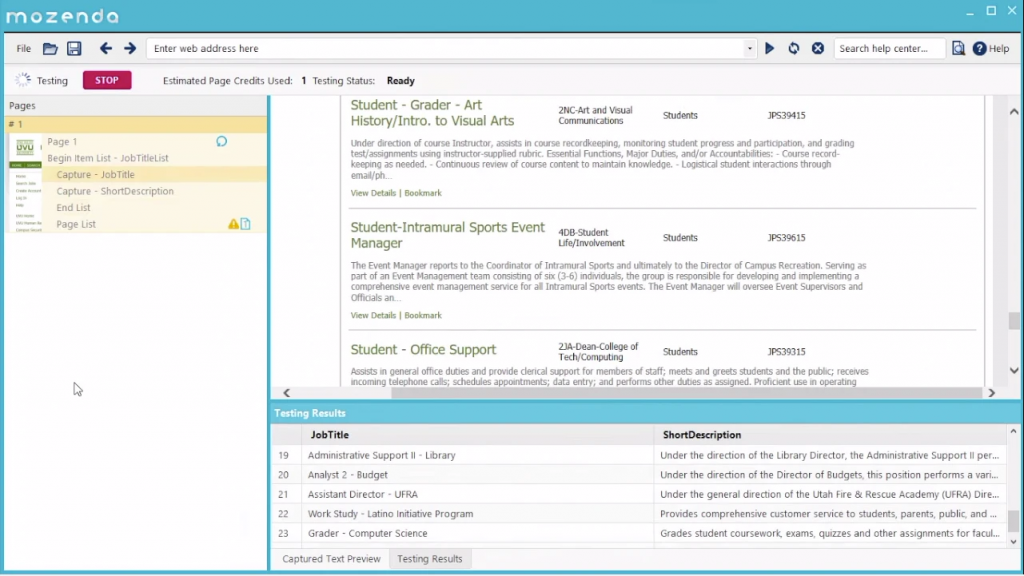
Mozenda is a robust web data extraction tool that enables you to automate the entire process. It also provides data visualization services. You don’t need to hire a data analyst anymore! It provides three services- cloud-hosted software, on-premise software, data services.
For a cloud-based self serve web page scraping platform, Mozenda has unrivalled in the market. With more than 7 billion pages scraped, Mozenda continues to serve enterprise customers from across the globe.
With mozenda, you can download data smoothly onto a spreadsheet, AWS or Azure the way you want. If you are a newbie, there are tutorials to explore and learn more about the product.
In all, Mozenda still rules the market for enterprise customers with scalable needs of web scraping.
Cost:
- Mozenda’s basic plan starting at $250/month for 20k processing credits/month and 2 simultaneous processes
- They also offer enterprise plans at $450/month for 1 million processing credits/year with 10 simultaneous processes.
Free Trial: Yes, 30 day free trial available
Type of Software: Downloadable software for Windows.
Features:
User Interface: Mozenda provides a point-and-click interface to create web scraping agents in minutes.
Which web data can it scrape?
- List
- Table
- Name value pairs
- Text
- Links
- images
Data Download formats: CSV, TSV and XML
Scrape and download images?: Yes
Scraping Listing pages, Detail Pages: Yes
Can it Scrape multiple pages / bulk pages?: Yes
Scrape data from pagination links, infinite scrolling, load more button
Can it scrape data by scheduling (scrape latest data by hourly, daily, weekly, etc)?: Yes
Custom Selector to select hidden / complex data: Mozenda supports XPath selectors only.
Custom Setup: Yes, only for enterprise level customers
Regex to find text that matches a pattern?: Yes
Can it handle website HTML changes?: No
Can it prevent scraper from getting blocked while scraping?: Yes
Mozenda provides different features such as Request Blocking, harvesting based on different geolocations, proxy pools, etc.
Data retention in days?: No mention
API integration: Using the Mozenda Web Services Rest API, customers can programmatically connect to their Mozenda account. This provides complete automation capabilities for setting search parameters, gathering results, updating collections, etc.
Scalable: Yes
Third-party Integration: They provide third party integration with Amazon S3, Microsoft Azure, Dropbox, FTP to publish data.
Learn about the product: Documentation: https://www.mozenda.com/help-center/
Customer Support:
- Free phone and email support for Premium
- Dedicated customer service manager for Enterprise customer
3. Diffbot
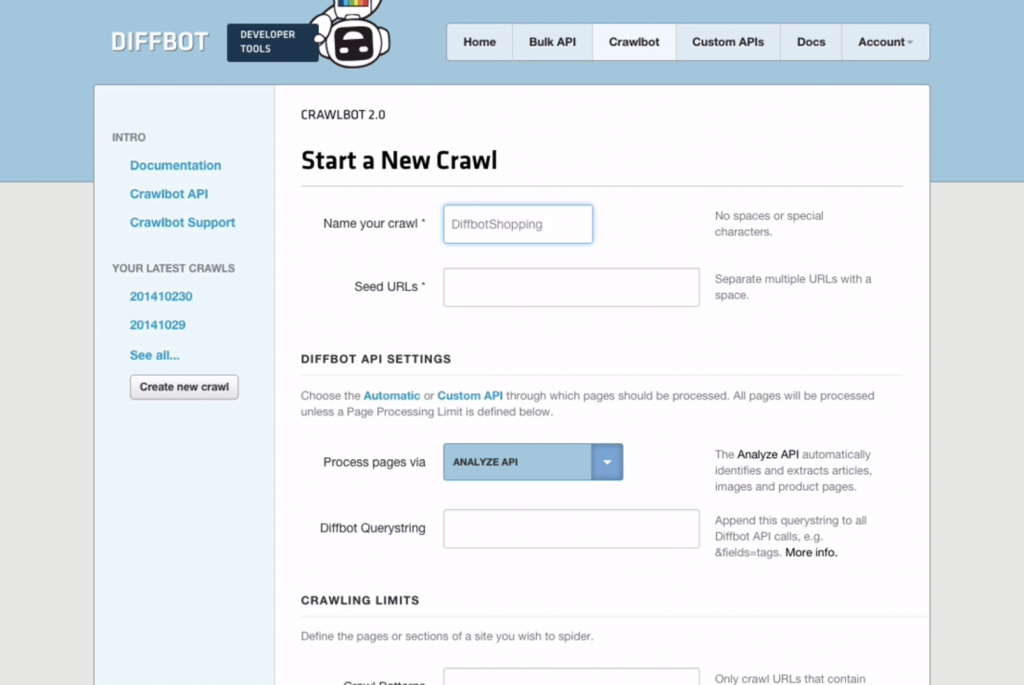
Diffbot specializes as a developer of machine learning and computer vision algorithms and public APIs for crawling data from web pages. The great thing about it is the way it automatically extracts web pages as structured data. No elaborate rules required for it.
If you are an enterprise with requirements of data crawling, Diffbot can be a great asset for you. It’s quite useful for scraping websites which experience frequent website changes. It’s amazing the way you can integrate it in minutes and get going.
You can scale up and still maintain accuracy. You also get video extraction API here.
Cost: Plan Starting from $299 for monthly 250,000 monthly credits
Free Trial: 2 week trial with Extraction API
Type of Software: Web Based
Features:
User Interface: For basic preconfigured extraction you just need to put a URL and Diffbot gives an output. But custom data extraction – user need very good knowledge of diffbot query, web crawling basics
Which web data can it scrape?
- Links
- Text
- Image URLs
- Metadata
- Video URLs
Data Download formats: CSV, JSON
Scrape and download images?: No Image URL scrape, no download
Scraping Listing pages, Detail Pages?: No
Can it Scrape multiple pages / bulk pages?: Yes Scrape data from pagination links, infinite scrolling, load more button
Can it scrape data by scheduling (scrape latest data by hourly, daily, weekly, etc)?: Yes
Custom Selector to select hidden / complex data: No
Custom Setup: Yes, only for enterprise level customers
Regex to find text that matches a pattern?: Yes
Can it handle website HTML changes?: No
Can it prevent scraper from getting blocked while scraping?: Yes
Data retention in days ?: No mention
API integration: Yes
Scalable: Yes
Third-party Integration: integration with Google sheet, Excel, Tableau, Salesfoce
Learn about the product: https://www.diffbot.com/resources/
Customer Support: Phone and Email Support
4. Import.io
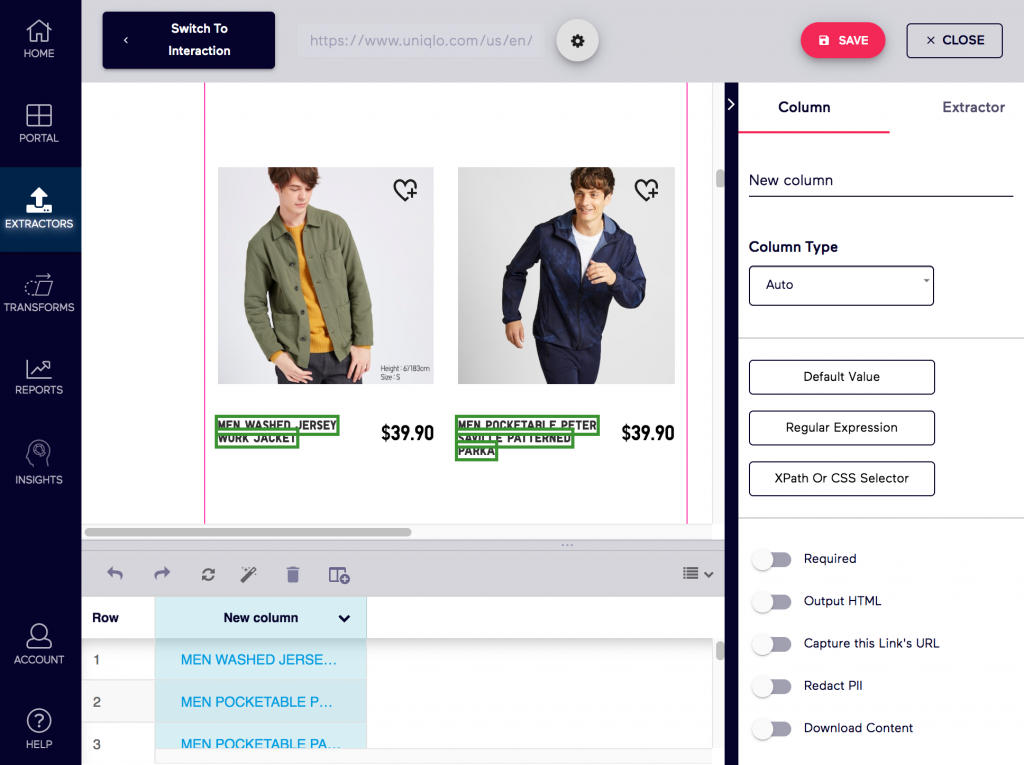
Import.io is a leading web scraping service. If you are an enterprise looking for a scalable solution for your web scraping needs, Import.io is what you need. Import.io is a hugely popular web-based platform that lets users scrape web data..
Whether it’s analytics, big data, data visualization, machine learning or artificial intelligence, Import.io is a tool that caters to a diverse set of projects. For its robust web scraping and data integration features, it stands out in the industry.
They have data cleaning and data visualization tools also.
It’s also outstanding for the way it’s made it easy for anyone to get started with Automatic data extraction. You don’t always need REGEX or XPath to get things done with Import.io. When it comes to customer service, Import.io excels there too.
Cost: no pricing disclosed
Free Trial: Yes, 1,000 URL queries per month with basic features
Type of Software: Web based tool
Features:
User Interface:
- It;s very easy to configure with import.io as they provide point and click selector to extract data from website
- They also provide data visualization tools to get insights from data
Which web data can it scrape?
- Links
- Texts
- Images
- Numbers
Data Download formats: JSON, CSV, HTML and Excel
Scrape and download images?: Yes
Scraping Listing pages, Detail Pages: Yes
Can it Scrape multiple pages / bulk pages?: Yes
Can it scrape data by scheduling (scrape latest data by hourly, daily, weekly, etc)?: Yes
Custom Selector to select hidden / complex data: Yes, supports Custom XPath selector to hidden / complex data
Custom Setup: Yes only for premium users
Regex to find text that matches a pattern?: Yes
Can it handle website HTML changes?: No
Can it prevent scraper from getting blocked while scraping?: Yes
Data retention in days?: Unlimited time for data retention
API integration: Yes
Scalable: Yes
Third-party Integration: Integration available with Tableau, Google Sheet
Learn about the product:
Customer Support: Ticket support
5. Dexi
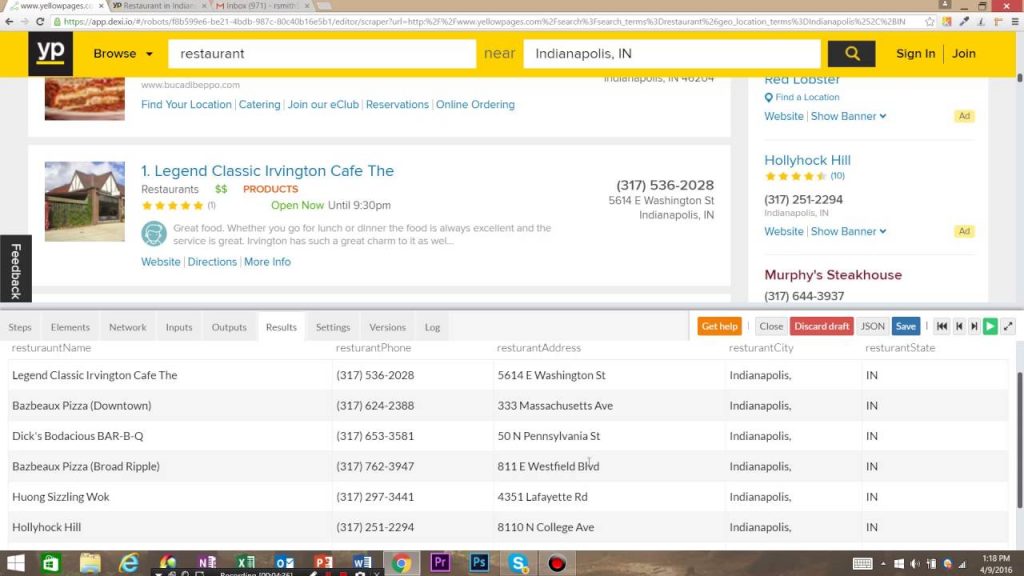
When it comes to applying external data and knowledge to intelligent automation, Dexi is no doubt one of the best tools in the industry.
For years, it has enabled businesses to extract and make use of the web data for automation and data mining.
The human precision with which you can scrape or interact with data makes it stand out among its peers. In terms of limitation, it should be noted that you need some programming and scraping skills to use it. Dexi has a very high learning curve.
In all, Dexi is a decent tool for diverse purposes.
Cost: Basic plans start at $119/month for 1 worker. (In order to run Dexi Robots, Pipes or Apps you will need execution capacity or virtual. You can build unlimited robots/processes, but only execute one concurrent process per Worker. You then have the choice between queuing up executions which will take longer or upgrade to the appropriate Dexi license bundle with more execution capacity.)
Free Trial: Yes
Type of Software: Web Based Software
Features:
User Interface: Dexi User Interface allows you to scrape or interact with data from any website with human precision.
Which web data can it scrape?
- Text
- Object
- Number
- Image
Data Download formats: CSV, XLS and JSON
Scrape and download images?: Yes
Scraping Listing pages, Detail Pages: Yes
Can it Scrape multiple pages / bulk pages?: Yes
Scrape data from pagination links, infinite scrolling, load more button
Can it scrape data by scheduling (scrape latest data by hourly, daily, weekly, etc)?: Yes
Custom Selector to select hidden / complex data: Yes
Custom Setup: Yes, for $249 / robot
Regex to find text that matches a pattern?: Yes
Can it handle website HTML changes?: No
Can it prevent scraper from getting blocked while scraping?: Yes
Yes, User need to import proxies
Data retention in days?: No mention
API integration: Yes
Scalable: Yes
Third-party Integration: Third Party Add Ons for connecting with APPS like Advertising, Analytics, Cloud Storage, Marketing , Captcha Solving Service, DataBase and etc
Learn about the product: Documentation: http://support.dexi.io/
6. Octoparse
As a modern visual web data extraction software, Octoparse stands out. If you need to scrape data in bulk, you can extract it without any coding knowledge.
It’s beautiful the way it automatically scrapes the data from any website and lets you save it as clean structured data in whatever format you wish. The other good thing is that it’s a free for life SaaS web data platform.
It provides great ready-to-use web scraping templates including Amazon, eBay, Twitter, BestBuy and many others. It lets you customize scrapers according to your highly specific web scraping requirements.
It works well for people who don’t have coding skills but need web scraping to be done. It would mean people who work in industries like e-commerce, investment, crypto-curreny, marketing, real estate etc. It’s also useful for enterprises with huge web scraping needs.
Sometimes, it may have trouble processing large tasks. It may sometimes reflect lack of consistency in the 4 modes of extraction. Its customer service may give you delayed responses sometimes.
Cost: Octoparse standard plan offers 100 crawlers with 6 concurrent cloud extractions at just $89/month.
Free Trial: Yes, unlimited pages scrape with limit of 10 crawlers
Type of Software: Downloadable software for Windows XP 7,8,10
Features:
User Interface: Experienced and inexperienced users would find it easy to use Octoparse to bulk extract information from websites, for most of scraping tasks no coding needed. It makes it easier and faster for you to get data from the web without having you to code
Which web data can it scrape?
- Table
- Text
- Links
- images
Data Download formats: CSV, Excel
Scrape and download images?: Yes
Scraping Listing pages, Detail Pages: Yes
Can it Scrape multiple pages / bulk pages?: Yes
Can it scrape data by scheduling (scrape latest data by hourly, daily, weekly, etc)?: Yes
Custom Selector to select hidden / complex data: Support Xpath selector
Custom Setup: Yes, starting from $399
Regex to find text that matches a pattern?: Yes
Can it handle website HTML changes?: No
Can it prevent scraper from getting blocked while scraping?: Yes Auto IP rotation
Data retention in days?: No mention
API integration: Octoparse API to deliver data automatically to your own systems.
Scalable: Yes
Third-party Integration: Octoparse currently not run with any integration.
Learn about the product: Documentation: https://helpcenter.octoparse.com/hc/en-us
Customer Support:
- Community for free users
- Email Support for premium customer
Customer Support: Live Chat
7. Parsehub
ParseHub is a powerful visual data extraction tool that you can leverage to fetch data anywhere from the web. It requires no technical know-how and makes your life easy when it comes to setting up and using a scraper. You can also create APIs from websites which don’t provide it.
Whether it’s interactive maps, calendars, search, forums, nested comments, infinite scrolling, authentication, dropdowns, forms,JavaScript, or Ajax, Parsehub can easily handle all this and more.
It’s got a free plan if you want to try it out. You can also explore its custom enterprise plans for data extraction on a scale. A wide variety of people like executives, software developers, data scientists, data journalists, business analysts, start-ups, pricing analysts, consultants and marketing professionals make use of Parsehub to the fullest.
Rescheduling and recurrent scraps- an API that lets you do whatever you want. This wins you over many times! Sometimes, it’s not as user-friendly as you would like it to be. You may have to do a few steps again and again. But it’s got some excellent features which make it the 2nd most powerful web scraping tool in the market!
Cost:
- Basic Plan Starts with $149/month for 20 projects (One project typically scrapes data from one website) with scraping speed – 200 pages scrape in 10 minutes
- Enterprise plan available for Custom number of projects and Dedicated scraping speeds across all running projects.
Free Trial: Yes, Parsehub offers 5 public projects in free trial with low scraping speed (200 pages of data in only 40 minutes).
Type of Software: Downloadable software for OS Mac, Windows and Linux.
Features:
User Interface:
- Browser Based Graphical User Interface where you can click to extract images, text, attributes and more
Which web data can it scrape?
- Texts
- Links
- Images
- Numbers (lat-long, prices, etc…)
- HTML
Data Download formats: JSON, CSV, and Excel
Scrape and download images?: Yes
Scraping Listing pages, Detail Pages: Yes
Can it Scrape multiple pages / bulk pages?: Yes
Scrape data from pagination links, infinite scrolling, load more button
Can it scrape data by scheduling (scrape latest data by hourly, daily, weekly, etc)?: Yes
Custom Selector to select hidden / complex data
Supports Xpath and CSS Selector tool to select hidden / complex data
Custom Setup: Yes, Parsehub can set up projects for you and deliver data on-demand for an extra fee or on our custom plan.
Regex to find text that matches a pattern?: Yes
Can it handle website HTML changes?: No
Can it prevent scraper from getting blocked while scraping?: Yes
IP rotation while scraping website
Data retention in days ?: 14 – 30 days based on plan
API integration: REST API to Download the extracted data in Excel and JSON
Scalable: With the highest plan you got speed of scraping 200 pages in 2 minutes.
Third-party Integration:
- Google Spreadsheet
- Tableau
Learn about the product:
- Documentation: https://help.parsehub.com/hc/en-us
- Q * A forum
- Videos
Customer Support: Online Chat
8. BrighData

It is easy to see why BrightData is the #1 web scraper and provider of ready-to-use datasets. Of all the web scraping tools we explore, BrightData topped the list on nearly all counts.
BrightData (est 2014 as Illuminati) started out as the premier proxy infrastructure platform. Very soon, they widened their service offerings by becoming a superior quality automated we data platform.
As an industry-leading web scraping platform, BrightData is a recipient of several awards and has over 760 granted patent claims. It serves over 15,000 happy customers that leverage web data over a wide variety of sectors.
Why BrightData stands out
Freedom from blocking
- Their Web-scraper IDE is built on unblocking proxy infrastructure. That means you don’t have to worry about being blocked while you’re collecting all the data you need.
Ready-made functions
- BrightData has a huge set of ready-to-use scraping functions and scrapers. That cuts away the time your developers would have otherwise spent in building and testing scrapers. Even your non-tech team can scrape data they need. All this translates to faster and easier scaling for you.
Compliance
- They are GDPR and CCPA compliant, which is an important factor for small businesses as well as enterprises using their services.
High ratings
- 4.8 out of 5 on TrustPilot
- 4.8 out of 5 on Capterra
- 4.7 out of 5 on G2
Cost: BrightData WebScraper IDE pricing starts at US$5 / 1,000 page loads. For annual plans (starting $500/month), you may contact them for a tailor-made quote.
Free Trial: Free trial is available upon request.
Type of software: Web based tool
Features
User Interface:
- Their clean interface makes it easy for even non-technical people to use the tool. Very little technical knowledge is required.
- Their ready-to-use functions make it easy for you to scrape data without having to write the entire code.
Which web data can it scrape?
BrightData can scrape the following:
- Table
- Text
- Videos
- Links
- Images
- JSON
Apparently there doesn’t seem to be much that BrightData isn’t capable of scrapping.
Data Download formats:
- JSON
- NDJSON
- CSV
- XLSX
Scrape and download images?: Yes
Scraping Listing pages, Detail Pages: Yes
Can it Scrape multiple pages / bulk pages?: Yes
Can it scrape data by scheduling (scrape latest data by hourly, daily, weekly, etc)?: Yes
Custom Selector to select hidden / complex data: Supports CSS Selector
Custom Setup: Yes, it’s available,starting at $390
Regex to find text that matches a pattern?: Yes
Can it handle website HTML changes?: No
Can it prevent scrapers from getting blocked while scraping?: Yes. Built -in proxy support.
Emulate a user in any geo-location with built-in fingerprinting, automated retries, CAPTCHA solving, and more.
Data retention in days?: Not mentioned
API integration: Yes. Once you log into your BrightData account, you’ll see all the different API integration methods.
Scalable: Yes
BrightData puts to use thousands of load-balancing super proxies. As a result, no matter how much the traffic, sessions and requests are easily managed. Consequently, the end-user is assured of both scalability and stability, along with the fastest proxy solution.
Third-party Integration: Currently not available
Learn about the product:
Customer Support:
- Email Support for premium customer
- Dedicated account manager for premium account
9. Apify
Apify is a fantastic tool that provides a web crawler for developers. Users just need to enter the URL of the page in the Apify crawler and specify the JavaScript code which will be used on every web page for scraping data.
It doesn’t matter who you are – a student, a journalist, start-up or an enterprise, Apify is a robust tool for all purposes. You would love Apify for its great documentation structures which can let you export any data to any required website rather than going through web scraping libraries.
You can log in from anywhere and seamlessly integrate it with any other tools as well. As a cloud-based service provider, it comes out with flying colours!
It’s priced quite affordably for anyone to be able to use it. In terms of limitations, it’s got a couple of things to work upon. Sometimes, it may get held up with firewalls while handling vast quantities of data. Pricing can be reduced somewhat if they allow the scripts to be used through replication.
Cost: Apify plans begin at $49/month with 100 compute units (For example, for 1 compute unit, you can crawl about 400 JavaScript-enabled web pages using headless Chrome, or about 5000 pages using a raw HTML parser.)
Free Trial: Yes; All features of the Apify platform are available on the free plan.
Type of Software: Web Based Tool.
Note: Apify also provides the web scraping library APIFY SDK open source library for developers.
Features:
User Interface: It;s easy to use for developers, but non-technical person it’s hard to use apify
Which web data can it scrape?
- Links
- Texts
- Images
- Videos
- Documents
- Email Address
- IP Address
- Phone Numbers
Data Download formats: JSON, CSV, HTML and Excel
Scrape and download images?: Yes
Scraping Listing pages, Detail Pages: No
Can it Scrape multiple pages / bulk pages?: Yes
User need to add javascript custom code to Scrape data from pagination links, infinite scrolling, load more button
Can it scrape data by scheduling (scrape latest data by hourly, daily, weekly, etc)?: Yes
Custom Selector to select hidden / complex data: Yes, but need to write custom code to select using Xpath and CSS
Custom Setup: Yes, Extra Charges on Custom Scraper.
Regex to find text that matches a pattern?: Yes (need to write custom code to apply regex)
Can it handle website HTML changes?: No
Can it prevent scraper from getting blocked while scraping?: Yes
Using residential IPs to avoid blocking
Data retention in days?: 7 – 30 days based on plan
API integration: Yes, to Manage, Build and Run apify actors
Scalable: Yes
Third-party Integration: Available integration on tools like Zapier, Integromat, Keboola, Webhooks, Transposit
Learn about the product:
Customer Support: Email
10. Grepsr Chrome
Gresper is a decent web scraping chrome extension tool. You can tag and mark data for extraction using an automated process. You can schedule extractions and download the data in various formats.
If you are a non-programmer, it works wonders for you. It’s easy to set up and start scraping data. The interface is not so difficult but you need to understand it on your own. In all, it’s a good tool for web scraping at a fair price.
Cost: Monthly Plan Starts from $20 for 25,000 records (Number of rows or record that can be collected) per month
Free Trial: Yes; 1000 records per month
Type of Software: chrome extension tool
Features:
User Interface: It’s easy to configure scraper with grepsr chrome extension
Which web data can it scrape?
- Links
- Texts
Data Download formats: JSON, CSV, RSS
Scrape and download images?: Not mention
Scraping Listing pages, Detail Pages?: Yes
Can it Scrape multiple pages / bulk pages?: Yes
User need to add javascript custom code to Scrape data from pagination links, infinite scrolling, load more button
Can it scrape data by scheduling (scrape latest data by hourly, daily, weekly, etc)?: Yes
Custom Selector to select hidden / complex data: No
Custom Setup: Yes, 129$ for custom setup
Regex to find text that matches a pattern?: Yes (need to write custom code to apply regex)
Can it handle website HTML changes?: No
Can it prevent scraper from getting blocked while scraping?: Yes
Data retention in days?: 30 – 90 days based on plan
API integration: Yes
Scalable: Yes
Third-party Integration: Dropbox, Google Drive, FTP, Box and Amazon S3
Learn about the product: Not found any documentation
Customer Support:
- Chat
What is web scraping used for?
Web Scraping has its applications in a host of diverse fields. It doesn’t matter what you are working on. Web scraping can help you extract relevant and reliable data for your specific project.
Vertical Search engines, classified sites, marketplaces
- There are certain websites that work as search engines for vehicle ads.
- You would naturally want to get hold of the data related to make and model of different vehicles. But it’s not easy to fetch such data from a website manually.
- Web scraping makes your task easier by getting the necessary data in an automated data and in a lightning quick way.
Retail and Manufacturing
- There are a number of applications when it comes to retail and manufacturing.
- First and foremost, it concerns the element of price. In an e-commerce business, you need to continuously keep track of your competitor’s price in order to decide your own pricing strategies. How will you get their price? To copy and paste the price of hundreds of products manually is not viable.
- But with the help of web scraping, you can constantly extract their pricing data on a continuous basis and accordingly finalize your prices. Most importantly, it’s an entirely automated process that produces accurate and reliable pricing data for you.
- If you are a manufacturer, you may want to keep tabs on the price that retailers use and whether they comply with the minimum price or not.
- But you cannot visit the website of so many retailers time and again to check it manually.
- With the help of a robust web scraping tool, you can monitor MAP compliance constantly and easily.
Data Science
- In data science, real-time analytics is a key concept. Real-time analytics means analyzing data right when the data becomes available.
- However, getting hold of data manually can time incredible efforts and countless man hours.
- This is why web scraping comes in so handy. You can easily get hold of the data you want and get started with real-time analytics.
- Likewise, predictive analysis also relies heavily on data. You cannot come up with patterns and probabilities without first having access to large quantities of data.
- Again, it’s web scraping that can make such large datasets available in no time.
- Web scraping has its application in natural language processing and machine learning training models.
Product, Marketing and Sales
- Marketing, as you know, depends on lead generation. How will you generate leads if you cannot get hold of large quantities of data?
- Naturally, you need to fetch vast datasets to generate leads. Web scraping can easily extract such datasets and power your lead generation.
- Likewise, for competitive analysis, you need a lot of data regarding a given competitor.
- It’s not possible to get so much data manually. Hence, web scraping comes in handy for extracting such large quantities of data that you can analyze and come with actionable intelligence regarding your competitor.
News and Reputation Monitoring
- Reputation monitoring is all about finding out how your customers feel about your company and brand.
- You need vast datasets to derive some insights regarding this. However, it’s difficult to get such data as it’s scattered across various social media and other sites.
- Web scraping is a powerful way to fetch such data and help you leverage it for reputation monitoring.
- Likewise, you can also get crumbs of news related data scattered all over the web and work out your strategies accordingly.
Frequently Asked Questions
Web scraping is legal as long as you scrape the public data. If you trespass and scrape copyrighted material or personal information for commercial purposes in an abusive fashion, it could lead to legal troubles. Also follow robots.txt to scrape data legally.
You can articulate your requirements
– Which data points you want to scrape
– Figure out approx URL you need to scrape
– Do you want to configure scraper by your own OR need data as a service
– Figure your budget
Based on it, you can survey the tools that match your requirements and budget. Don’t forget to consider customer service while finalizing the tool.
– ProWebScraper is one of the cheapest web scraping tools. You can get a free trial and it has also got different affordable plans.
– Other cheapest tool is : Octoparse and Parsehub.
Below web scraping tools are easy to use and Do-It-Yourself solutions
– Octoparse
– ProWebScraper
– Grepsr
Almost all tools provide some or the other custom web scraping solutions.
Scrapy and Beautifulsoup are most popular & open source libraries for web scraping.
Do you have user experience with any of the above web scraping tools?
If yes, we would like to hear that. Please comment your experience about any of the above company.
